The Best LLM for Coding in June 2026 Is Not a Model. It Is a Two-Tier Stack.

Hey guys, Mr. Technology here.
Claude Fable 5 launched on a Tuesday and the US government killed it by Friday. Claude Opus 4.8 is the best coding model in production today, with a system card that admits \"perfect jailbreak resistance is not currently possible.\" The SWE-bench Verified leaderboard is flat — ranks 5 through 10 sit inside 0.5 points of each other, which is statistical noise. Kimi K2.7-Code, a fully open-weights Chinese model, beats Opus 4.8 on the tool-use benchmark that matters most for production agents. DeepSeek V4-Pro-Max ties Gemini 3.1 Pro on SWE-bench Verified at 80.6% and tops LiveCodeBench at 93.5. Z.ai shipped GLM-5.2 with a 1M-token context at 5:21 PM ET on June 13, the exact minute the Fable 5 suspension took effect. The open-weights vendors are now Anthropic-compatible from day one, which means a model swap is a config change.
If you are still asking \"which LLM is best for coding?\" you are asking the wrong question. The right question is: what is the cheapest, safest, most portable two-tier agent stack I can stand up in a weekend that survives my model vendor getting government-pulled next quarter? That is the question this post answers.
The 0.5-Point Spread Tells You Where the Frontier Is
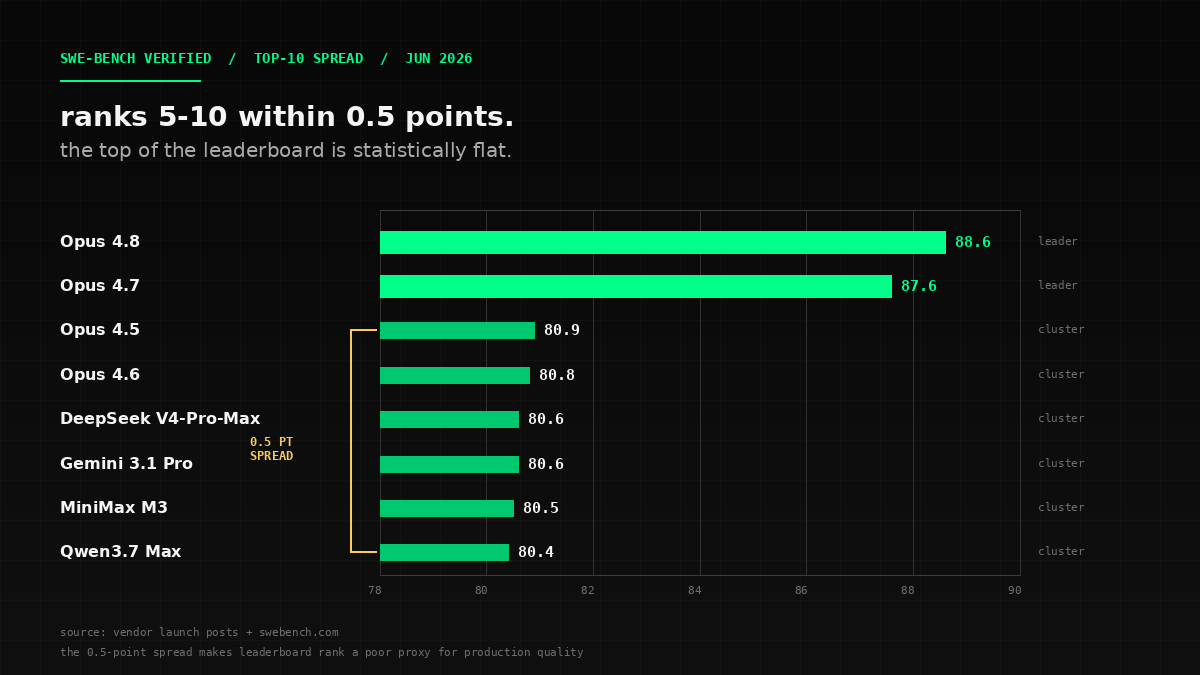
The June 2026 SWE-bench Verified leaderboard is the most important data point in this entire post, and the headline is not \"X is on top.\" The headline is the spread. Ranks 5 through 10 — Opus 4.5, Opus 4.6, DeepSeek V4-Pro-Max, Gemini 3.1 Pro, MiniMax M3, Qwen3.7 Max — are all within 0.5 points of each other. Per Morph's SWE-bench Pro synthesis and the official SWE-bench leaderboard, the middle of the leaderboard is statistically flat. The gap from rank 5 to rank 1 is about 8 points, but the gap from rank 5 to rank 10 is noise.
This is the new world. The leaderboard topper is not a meaningful differentiator for the bulk of production work. What is a meaningful differentiator is the system around the model — the harness, the memory layer, the cost discipline, and the fallback architecture when your model vendor gets pulled for 72 hours. Simon Willison called this in his February 2026 SWE-bench update: \"Opus 4.5 beats Opus 4.6, but only by about a percentage point.\" That percentage point is not the story. The story is the three Chinese models in the top 10.
Why It Matters
Three things changed between December 2025 and June 2026, and each one shifts the answer to \"best coding LLM\" away from picking a single model.
The closed frontier is now regulatorily fragile. Claude Fable 5 launched on June 9, 2026 and was suspended on June 12 by US export control authority, per Anthropic's own statement, for a capability that \"is widely available from other models (including OpenAI's GPT-5.5) and is used every day by the defenders who keep systems safe.\" Three days. The full arc is in our Fable 5 launch coverage. The precedent is now structural: any frontier release can be killed in 72 hours for a capability the rest of the frontier already has. If your production stack runs on a single closed-frontier model, you are one regulatory letter away from a fire drill. The Fable 5 suspension is not an outlier. It is the template.
Open-weights caught up on the benchmarks that matter. As of June 2026, Kimi K2.7-Code hits 81.1% on MCPMark Verified, beating Opus 4.8's 76.4% on the same tool-use benchmark. DeepSeek V4-Pro-Max ties Gemini 3.1 Pro on SWE-bench Verified at 80.6% per the Morph DeepSeek V4 analysis and tops LiveCodeBench at 93.5 — the highest coding-benchmark score of any model as of June 2026, confirmed by CAISI's independent NIST evaluation. GLM-5.2 shipped with a 1M-token context and an MIT license (per our GLM-5.2 launch coverage), beating Anthropic and OpenAI to the post-Fable-5 narrative. For pure code generation and tool use, the open tier is no longer a fallback. It is a viable primary.
The agent stack is now portable across vendors. Every major open-weights model ships an Anthropic-compatible endpoint on day one. Kimi K2.7-Code, GLM-5.2, and DeepSeek V4 all expose /api/anthropic routes. Claude Code, Cline, OpenCode, OpenClaw, and Cursor all default to the Anthropic SDK. You can swap your primary from Opus 4.8 to Kimi K2.7-Code with an environment variable change, no agent code rewritten. The portability problem is solved. The lock-in problem is solved. The reason every team is not already running a two-tier stack is inertia, not architecture.
These three changes have a single combined implication: picking a single \"best\" model in 2026 is a category error. The right architectural answer is a two-tier stack with a frontier primary and an open-weights fallback, both behind the same Anthropic-compatible API, so a vendor going down — regulatory pull, outage, bankruptcy, or pricing shock — is a config change, not a fire drill. This is not the same argument as \"use a cheaper model.\" It is the argument that the model selection is the cheapest, lowest-leverage decision in your stack, and the system around the model is where the real engineering lives. The fastest way to ship faster than your competition in 2026 is not to find a better model. It is to build a system that does not break when your current model gets pulled.
The Candidates
I am reviewing six models that matter for coding in June 2026. Three closed-frontier, two open-weights flagship, one cheap-and-deep closed option. Each gets a release date, vendor, pricing, the two benchmarks that matter, a real-world signal, and a \"best for\" call. No hand-waving.
Claude Opus 4.8 (Anthropic, 2026-05-28)
The current top of the coding mountain. Anthropic's launch post reports 88.6% on SWE-bench Verified, 69.2% on SWE-bench Pro on the vendor scaffold, and 84% on Online-Mind2Web for computer use — the highest of any frontier model. The price stayed at $5/M input and $25/M output, same as 4.7, and the fast mode is 3x cheaper than the previous generation. Tester quotes: Devin reports it \"fixes the comment-verbosity and tool-calling issues we saw with 4.7,\" Cursor reports \"notably better judgment, asks the right questions, catches its own mistakes,\" and Thomson Reuters reports it is the first model to break 10% on the all-pass standard on their Legal Agent Benchmark.
The weaknesses are real. The vendor-claimed 69.2% on SWE-bench Pro drops to roughly 52% on Scale's standardized SEAL public set and 37-40% on the commercial set per the Morph synthesis — a 17-30 point gap attributable to scaffolding, not model quality. The Opus 4.7+ tokenizer change produces up to 35% more tokens per request than pre-4.7 Claude, so effective per-task cost is higher than the per-token rate suggests. And the system card openly admits that \"perfect jailbreak resistance is not currently possible\" — the regulatory and PR risk on this model is structural, not theoretical.
Best for: Long-horizon, multi-file refactors and high-stakes production code review where the cost of a wrong answer is high (legal, financial, security). The default primary in a two-tier stack when the agent's work is the kind of work where Opus-level judgment matters.
Claude Sonnet 4.6 (Anthropic, GA 2026-03)
The workhorse. 79.6% on SWE-bench Verified at roughly one-fifth the cost of Opus 4.8 — the best price-performance point in the Anthropic line for everyday coding per Morph's Claude benchmarks. Same Anthropic API surface, so model swaps in a two-tier stack are config changes, not rewrites. Claude Code, Cursor, Cline, OpenCode, and OpenClaw all default to Sonnet for routine work. The $3/M input and $15/M output pricing, with prompt caching at $3.75/M writes and $0.30/M reads, makes the cost story very attractive for high-volume code generation.
The weaknesses: material drop-off on very long-context agent loops (1M+ token sessions) compared to Opus 4.8, less reliable on novel architectural decisions, and a 43.6% on Scale's standardized SWE-bench Pro public set is mid-pack, not top-tier.
Best for: Day-to-day code generation, PR review, test writing, doc generation, and the bulk of Claude Code sessions that do not need Opus-level judgment. The right primary for 80% of agent traffic. If you are running a single-model stack, this is the model you should be running.
GPT-5.5 (OpenAI, 2026-04-23)
The best OpenAI coding model currently shipping. 58.6% on SWE-bench Pro per OpenAI's launch post on the vendor scaffold, and the only closed model that comes close to Opus 4.8 on long-running Super-Agent benchmarks. Best-in-class computer use — Anthropic uses GPT-5.5 as the comparison point for Opus 4.8 in their launch post. Codex CLI + ChatGPT desktop is the smoothest \"agent on your laptop\" experience, and the OpenAI Apps SDK is the most mature third-party plugin surface in the industry. Note that GPT-5.4 (March 2026) still leads Scale's standardized SWE-bench Pro public leaderboard at 59.1% on identical scaffolding — the apples-to-apples leaderboard topper — which is the more interesting data point than GPT-5.5's vendor-scaffold claim.
The weaknesses: per-token cost is the highest of the frontier, at roughly $5-15/M input and $30/M output depending on tier (instant / thinking / pro). The vendor-vs-standardized gap is the widest of the major labs — vendor claims run 15-25 points above Scale SEAL on the same model, eroding trust in marketing numbers. Closed source, no on-prem, full US export-control exposure.
Best for: Mac/desktop power users running Codex CLI as their primary coding surface, teams already invested in the OpenAI Apps SDK plugin ecosystem, and competitive programming or one-shot code generation where the model has to be the smartest single shot, not the most reliable agent. If your dev environment is a Mac, your IDE is VS Code or Cursor, and your plugins are OpenAI-native, GPT-5.5 is the right primary. The HN/Reddit consensus holds: \"GPT-5.5 is the smartest single shot, Claude is the best agent, DeepSeek/Kimi are catching up fast.\"
Gemini 3.1 Pro (Google DeepMind, 2026-02-19)
80.6% on SWE-bench Verified per Google's launch blog — tied with DeepSeek V4-Pro-Max and within 8 points of Opus 4.8, at $12/M output (less than half of Opus pricing). The 1M-2M token context window (depending on tier) is the only closed-model context window that is actually usable at frontier-tier reasoning quality. Native multimodal coding: it can ingest screenshots, Figma exports, and PDF specs in the same context as the codebase, with no separate vision pipeline. First model to break 77% on ARC-AGI-2 and 100% on Google's code-execution eval.
The weaknesses: drops to 32.2% on Scale's SWE-bench Pro commercial set versus 46.1% public — the largest public-to-private drop in the top 5, suggesting some overfit to public test patterns. Tool-call reliability on long agent loops is consistently reported as worse than Claude and GPT-5.x — devs describe it as \"great at the first turn, then drifts.\" Vertex AI and Gemini API ergonomics are still a step behind the OpenAI and Anthropic SDKs. Locked behind Google's billing and quota model — no self-host, no export to other clouds.
Best for: Multimodal coding tasks (screenshot-to-code, Figma-to-React, video-to-spec) where the input is not pure text, repo-scale refactors where 1M+ token context is a real asset, and cost-sensitive teams that need Opus-class reasoning on Google's billing. The right answer when the input is half-screenshots, half-codebase.
Kimi K2.7-Code (Moonshot AI, 2026-06-12)
The most strategically important release of the month. Open weights under a modified-MIT license, 1T-parameter MoE with 32B active per token, runs on a single 8xH100 node at full precision or quantized on a 4xA100 box. Beats Opus 4.8 on tool use: 81.1% on MCPMark Verified versus 76.4% on the same eval per Moonshot's release (cross-referenced in our Kimi K2.7-Code release coverage). 30% fewer reasoning tokens than K2.6, native INT4 quantization. The strategic move is the Anthropic-compatible API at $0.95 input / $4.00 output per million tokens — point at it from Claude Code or Cline with one env var change and the agent code does not need to change.
The weaknesses: the modified-MIT \"advertising clause\" is unusual — derivative deployments must include a specific attribution notice; check with counsel before shipping into a commercial product. Vendor-reported numbers; independent SEAL-style standardized runs are still pending, so expect some compression on private benchmarks. Inference tooling is less mature than the Anthropic and OpenAI ecosystems — expect to spend engineering time on vLLM/SGLang tuning for production scale. English-language training data is smaller than the US labs; non-Python languages (Rust, Elixir, OCaml) lag behind Claude and GPT.
Best for: The open-weights primary in a two-tier agent stack. Specifically, the right answer to \"what do we run when Claude is unavailable, suspended, or too expensive?\" If Fable 5 is the regulatory risk, Kimi K2.7-Code is the architectural insurance. The Anthropic-compatible endpoint means a model swap is a config change, and the license means the model is yours, not rented.
DeepSeek V4-Pro-Max (DeepSeek, 2026-04-24)
80.6% SWE-bench Verified (open weights) — matches Gemini 3.1 Pro, within 8 points of Opus 4.8, and was the first open-weights model to break 80% on this benchmark. 1.6T-parameter MoE with only 40B active per token, 1M-token context window, roughly 20% the price of GPT-5.5 on API. The Pro config scored 93.5 on LiveCodeBench, the highest coding-benchmark score of any model as of April 2026 per Morph's DeepSeek V4 analysis. CAISI's independent NIST evaluation confirmed the Pro config performs close to vendor claims on standardized tests — the gap to the closed frontier is real but small.
The weaknesses: CAISI's standardized run still shows a 7-8 point gap to Opus 4.7 / GPT-5.5 on the most rigorous subset. On non-coding tasks (agentic long-context, multimodal), DeepSeek lags Claude and Gemini more visibly than on pure code generation. US/EU regulatory exposure is significant — DeepSeek's data and hosting posture is under active review, and some enterprise procurement teams will not allow it on principle. V4-Flash exists at $0.14/M for cost-sensitive workloads, but it is materially weaker on multi-file agent tasks.
Best for: Cost-performance king for high-volume code generation at the open tier. When Kimi K2.7-Code is not the right cultural or political choice, or when you want LiveCodeBench-leading coding performance specifically, V4-Pro-Max is the second open-weights slot in the two-tier stack. Also the right answer if you need a coding model that is great at competitive programming and benchmark-driven code generation specifically.
Benchmarks Reality Check
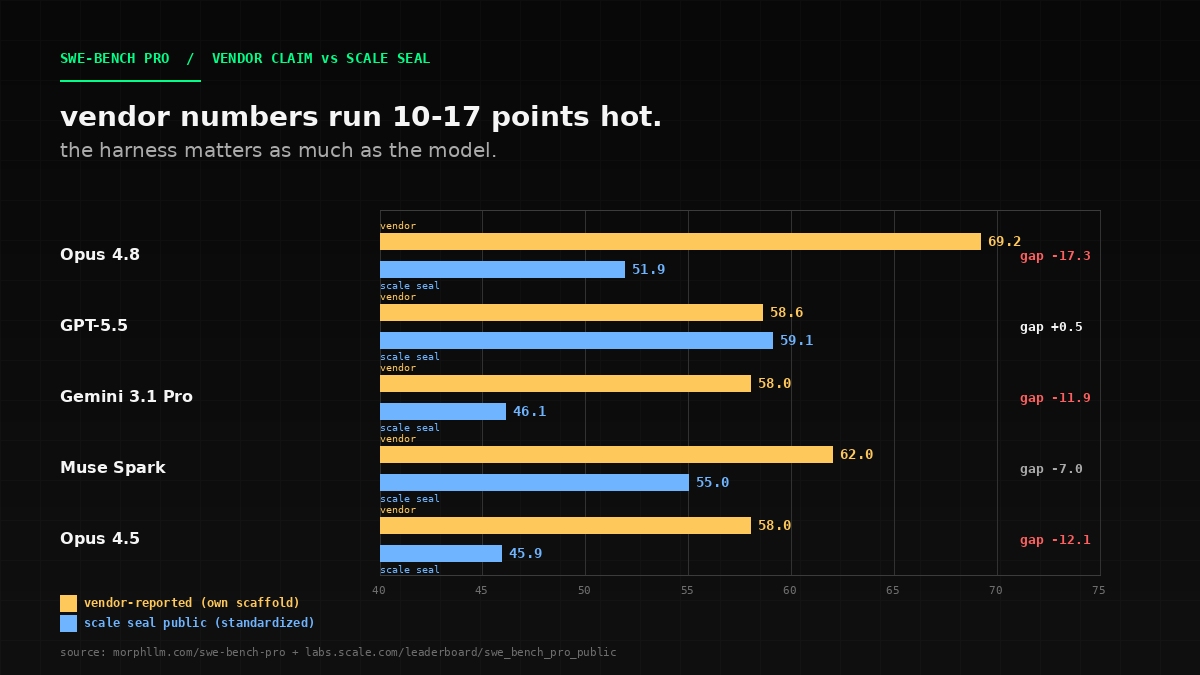
Almost every \"best coding LLM\" list in 2026 is broken in the same way: it quotes vendor numbers and compares them to other vendor numbers. The comparisons are not valid.
Here is what the vendor-vs-standardized gap looks like on SWE-bench Pro, using the Scale SEAL public leaderboard as ground truth. Anthropic claims 69.2% for Opus 4.8 on their scaffold. Scale's standardized run of the best Claude (Opus 4.6 thinking) scores 51.9% — a 17-point gap. OpenAI claims 57% for GPT-5.3-Codex on their scaffold; Scale's run of the same family scores 41%. When a vendor publishes a number 10-30 points above the Scale SEAL public leaderboard, it is a vendor-scaffold number. The right move is to use Scale's standardized public set as the ground truth, and treat vendor claims as marketing.
The public-to-private drop is the second signal nobody is reporting. On SWE-bench Pro, the gap between the public set (731 tasks from open-source repos) and the commercial set (276 tasks from 18 proprietary startup codebases) is the most predictive signal for production model selection:
| Model | Public Set | Commercial Set | Drop |
|---|---|---|---|
| Opus 4.6 thinking | 51.9% | 47.1% | -5 points |
| GPT-5.4 (xHigh) | 59.1% | 43.4% | -16 points |
| Gemini 3.1 Pro | 46.1% | 32.2% | -14 points |
| Opus 4.5 | 45.9% | 23.4% | -22.5 points |
| GPT-5 | 41.8% | 14.9% | -27 points |
Opus 4.6's drop is the smallest in the top 5. That is why Opus 4.6 — a 4-month-old model — is still the best pick for production code on private codebases despite no longer holding the leaderboard topper. The public-to-private drop is the single most predictive signal for production model selection, and every \"best LLM\" list in 2026 is choosing from the public column and pretending the column does not matter.
HumanEval and the legacy HumanEval+ splits are saturated across the frontier at >92%. They are not a 2026 differentiator. SWE-bench Verified is also showing saturation at the top — the 0.5-point spread across ranks 5-10 is the smoking gun. The benchmarks that actually matter in 2026 are SWE-bench Pro (both public and commercial splits), MCPMark Verified for tool use, Terminal-Bench Hard v2.0 for full agent loops, LiveCodeBench for contamination-resistant competitive programming, and Aider Polyglot for multi-language code editing. If a vendor is not reporting numbers on those, the numbers they are reporting are not useful.
Use-Case Matrix

The fastest way to make a model decision is to map the workload to the model. Here is the matrix I run for teams that ask me \"which one\":
If you need a primary for a 24/7 production agent on a real codebase: Sonnet 4.6 (cost + reliability) or Opus 4.8 (judgment + accuracy). The default is Sonnet. Move to Opus when the cost of a wrong answer (legal, financial, security) is higher than the 5x cost delta.
If you need a fallback that survives your primary being government-pulled: Kimi K2.7-Code (best open-weights tool use, Anthropic-compatible) or DeepSeek V4-Pro-Max (highest LiveCodeBench, second-best tool use). The default is Kimi for the API compatibility. Move to DeepSeek when you specifically need LiveCodeBench-leading coding performance.
If you need the smartest single-shot code generation (one prompt, no agent loop): GPT-5.5. The Codex CLI + ChatGPT integration is the smoothest single-shot experience, and GPT-5.4 is the apples-to-apples standardized leaderboard topper.
If you need multimodal input (screenshots, Figma, video, PDFs): Gemini 3.1 Pro. The 1M-2M context window and native multimodal pipeline are unmatched. Use Opus 4.8 only when the agent's job is judgment-heavy code review on top of the multimodal input.
If you need long-context, repo-scale refactors (1M+ tokens): Gemini 3.1 Pro (best in class for actual 1M usability) or Opus 4.8 (best in class for agent judgment at long context). Sonnet drops off materially at 1M+.
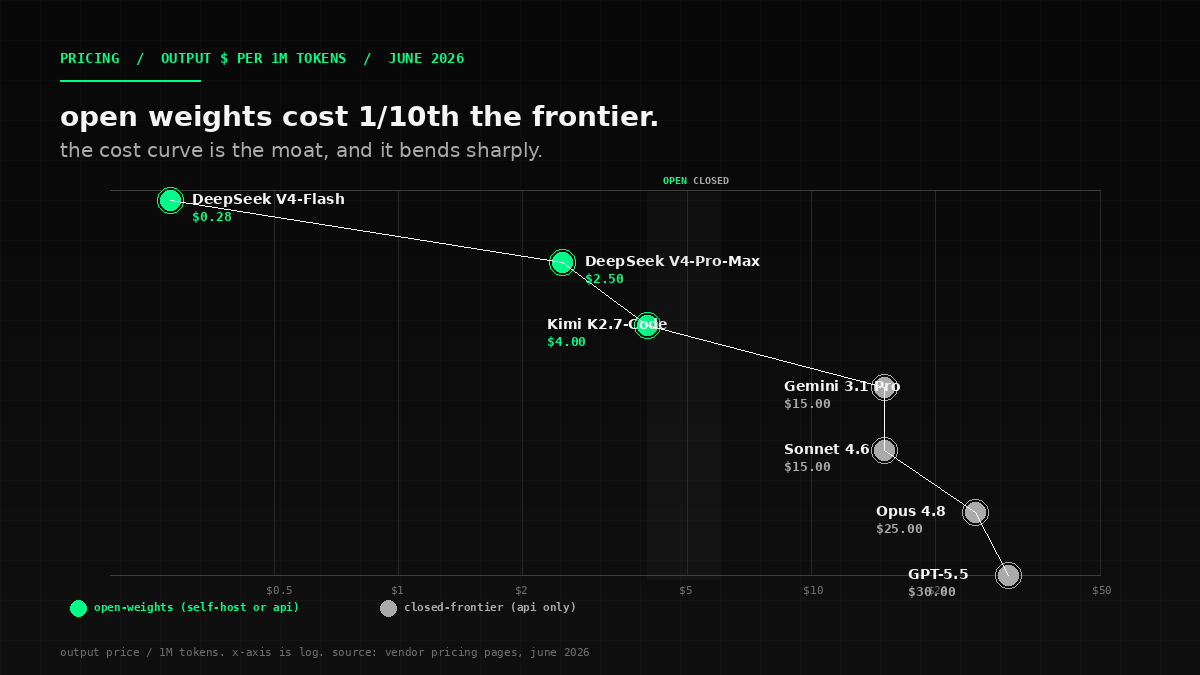
If you need to ship on a budget: Kimi K2.7-Code at $0.95/$4.00 per million tokens with prompt caching enabled. Add Claude prompt caching on whichever Anthropic model you run for an 80% bill cut on the cached portion.
If you need a coding model you can fine-tune on your own data: DeepSeek V4-Pro-Max (fully open, permissive license) or Kimi K2.7-Code (open, modified-MIT with advertising clause — check with counsel). No closed model is fine-tunable.
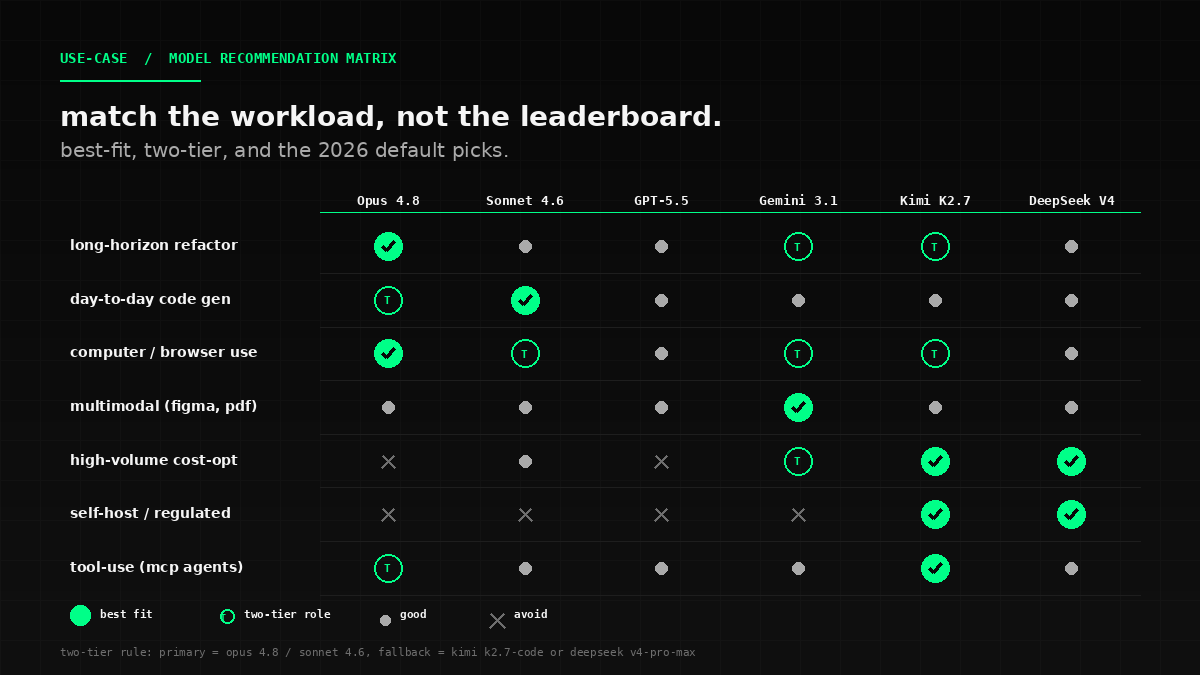
The hardest decision is not \"which model.\" It is \"which two models, behind which API, with which routing rules.\" My default recommendation for 2026 is: Sonnet 4.6 as the daily-driver primary (or Opus 4.8 if the work is judgment-heavy), Kimi K2.7-Code as the fallback behind the same Anthropic-compatible API, and a routing layer that triggers the fallback on rate limits, cost thresholds, or primary availability. The routing is the engineering. The model is the config.
The Verdict
The \"best LLM for coding\" question is now an infrastructure question, not a leaderboard question. The Fable 5 arc and the 0.5-point SWE-bench Verified spread are the same signal: the leaderboard topper is not a meaningful differentiator, and picking a single winner is an architecture that loses to a regulatory pull. The right answer is a two-tier stack.
The default stack I would ship this weekend:
1. Primary: Claude Sonnet 4.6 for day-to-day, Claude Opus 4.8 for judgment-heavy work (routing by task type or by a simple complexity classifier on the prompt). Same Anthropic API surface, same SDK, same model swap as a config change. Prompt caching enabled on the system prompt and any long-context payloads — see our 5-minute prompt caching tutorial for the cut-and-paste code. The 80% bill cut on the cached portion is the single highest-ROI move in your stack. 2. Fallback: Kimi K2.7-Code at https://api.moonshot.cn/anthropic (or the equivalent Anthropic-compatible endpoint), pointing at the same Claude Code / Cline / OpenCode / OpenClaw installation via ANTHROPIC_BASE_URL and ANTHROPIC_DEFAULT_*_MODEL env vars. Same SDK, same agent code, same prompts. Trigger the fallback on rate limits, cost thresholds, or primary availability — not on model quality, which is fine on both sides for the bulk of agent work. 3. Optional secondary fallback: DeepSeek V4-Pro-Max for LiveCodeBench-leading single-shot code generation, behind the same Anthropic-compatible endpoint pattern. Use this when the primary is down AND Kimi is unavailable AND the workload is a one-shot competitive-programming-style task.
The two-tier stack is the architectural answer to Fable 5. The 72-hour shutdown was the proof point: any model can be pulled, and the response is not \"pick a model that will not be pulled\" — there is no such model — but \"make a model swap a config change.\" Routing on availability, not on leaderboard rank, is the new design pattern.
The biggest cost lever is not model selection. It is harness and memory. The TiDB Agent State Stack that shipped on June 11 (mem9, drive9, TiDB Cloud Zero) gives agents durable, portable memory for the first time. Adding prompt caching saves 80% on cached-prefix tokens. If you swap Opus 4.8 for Sonnet 4.6 and save 60% on the model bill, you have saved less than turning on prompt caching and saving 80% on the same Opus 4.8 calls. Teams that optimize model choice before optimizing memory and harness are tuning the wrong knob. The model matters. The system around the model matters more. If your \"vibe coding\" stack is shipping code at 10x velocity and you have not built the engineering judgment to keep that code maintainable, you are buying a 2028 mortgage at 2026 prices — see our opinion piece on vibe coding for the maintenance bill coming due.
What to Watch
MCPMark Verified leaderboard moves. The first time an open-weights model beat the closed frontier on a non-vendor-controlled tool-use benchmark was June 2026 (Kimi K2.7-Code 81.1% vs Opus 4.8's 76.4%). This number moves monthly. Independent Scale SEAL runs of Kimi are pending as of this post. If the standardized run confirms the vendor claim, the open-weights tier crosses the threshold where it is a primary, not a fallback, for tool-use-heavy agent workloads.
Fable 5 / Mythos 5 regulatory arc. The US government has now demonstrated the ability to suspend a frontier model in 72 hours for a capability the rest of the frontier has. The next frontier release from any lab will be evaluated against this precedent. Watch for: (a) whether Anthropic releases a successor to Fable 5 in the next 90 days, (b) whether the next release ships with export-control-resistant defaults (geo-fenced compute, no foreign-national access at the inference layer), and (c) whether OpenAI / Google / Moonshot / DeepSeek face similar directives. The regulatory template is now structural. Every lab is recalibrating release strategy in response.
Open-weights releases: GLM-5.2, Qwen3-Coder, MiniMax M3. Z.ai shipped GLM-5.2 with a 1M-token context and an MIT license on June 13 — the same minute the Fable 5 suspension took effect (per our GLM-5.2 coverage). The 1M-token context is real, the open-weights roadmap is real, and the Anthropic-compatible endpoint is real. Qwen3-Coder and MiniMax M3 are rumored for late Q3 2026; both are positioned as competitive with the closed frontier on code generation specifically. Watch the MoE-active-parameter counts and the per-token economics — the 5-20% cost ratio is the strategic point.
Harness innovation. The biggest cost lever is not the model, it is the system. Watch for: portable agent memory layers (TiDB Agent State Stack, mem9, drive9), prompt caching at the framework layer (not just the SDK layer), and Anthropic-compatible API adapters that turn \"swap model\" into a one-line config change. The two-tier stack is the architectural pattern. The infrastructure to make it cheap and reliable is what matures next.
The leaderboard is flat. The system around the model is the lever. The fallback is the architecture. Build accordingly.
— Mr. Technology
Release date: June 16, 2026. Coverage: Claude Opus 4.8 (Anthropic launch), Claude Sonnet 4.6 (Morph benchmarks), GPT-5.5 (OpenAI launch), GPT-5.4 (OpenAI launch), Gemini 3.1 Pro (Google blog, DeepMind model card), Kimi K2.7-Code (Hugging Face, Moonshot announcement), DeepSeek V4-Pro-Max (Morph analysis, Lightning.ai comparison, CAISI/NIST evaluation), Claude Fable 5 / Mythos 5 launch and suspension (Anthropic Fable launch, Anthropic suspension statement), SWE-bench February 2026 update (Simon Willison), SWE-bench Pro synthesis (Morph SWE-bench Pro), Scale SEAL SWE-bench Pro public leaderboard (Scale). Benchmark data: SWE-bench Verified (official, third-party tracker), SWE-bench Pro (Scale SEAL public and commercial sets), MCPMark Verified, Terminal-Bench Hard v2.0 (official, third-party), LiveCodeBench (official), Aider Polyglot (official, synthesis).